How to start?
A data pipeline is a chain of services for ingesting, processing, and storing data. Extra components on top allow querying data and presenting the results. For example, Hadoop and its ecosystem provide such services and components. Hadoop went a long way from its original set of services: storage (HDFS) and compute (MapReduce). Its growing number of services and the along growing complexity is hard to keep up with. On top of that, these days more and more deployments are utilizing the cloud.
Service selection is easier when committing to a particular cloud provider. The providers have architecture blueprints with service recommendations for many use cases. Cloud providers also offer hosted platform alternatives. For example, Microsoft Azure offers Event Hubs for Apache Kafka use cases.
What to expect from a data pipeline? What is batch and stream processing? What building blocks are available and how to chain them to build a robust data pipeline? I am going to answer these questions so let’s get started!
Data pipelines
Data pipelines expel manual steps from data engineering. Many places use the term ETL (Extract, Transform, Load) and data pipeline to refer to the same process. In reality, data pipeline is a broader term that encompasses ETL. ETL pipelines are batch-oriented. They run, e.g., every day at 1:00 AM and extract data from a system; transform, load it into another. Contrary, data pipelines generally refer to moving data from a system to another. Steps may transform the data. Steps may process it (near) real-time; in a continuous flow (called streaming); or in batches. The final steps may load the data into different target systems. The load target may be an on-premises data lake or an object store like Amazon S3.
A well-known example of a blueprint for data pipelines is the Lambda Architecture [1]. It introduced two parallel pipelines on the same data sources. One pipeline for streaming (“speed layer”) and one for batch processing (“batch layer”). An extra layer (“serving layer”) stores the output and responds to ad-hoc queries:
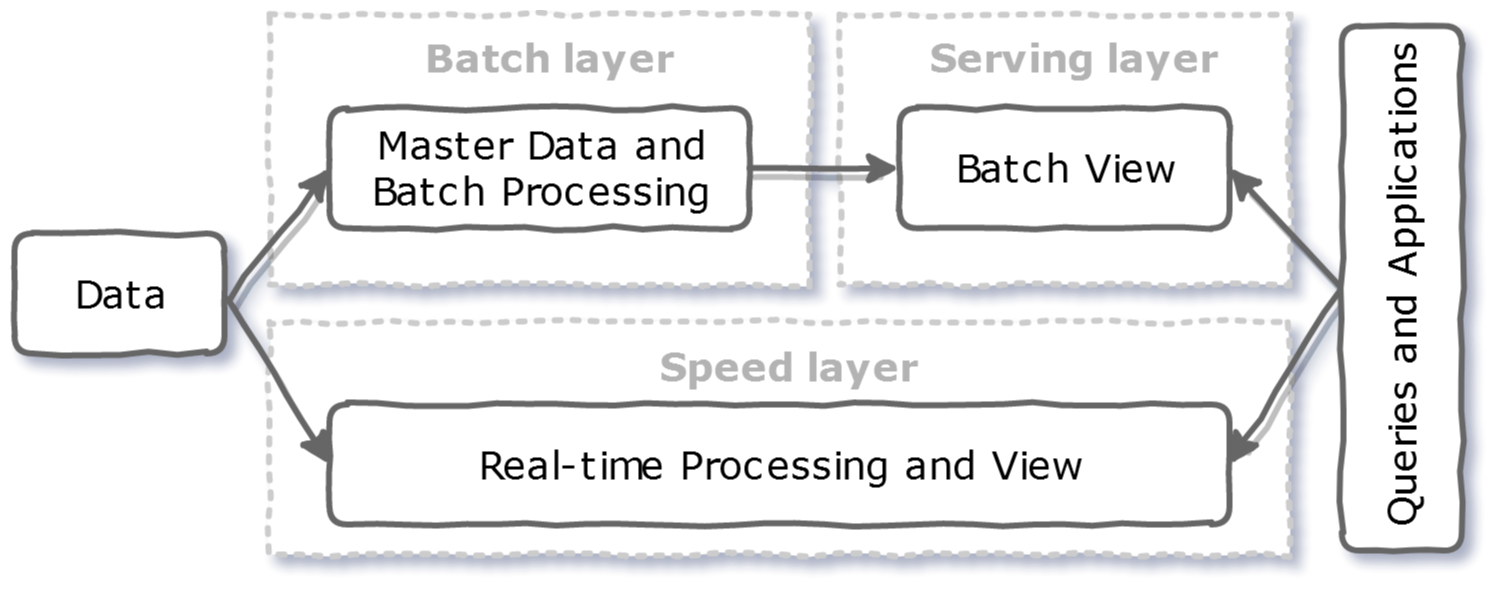
The Lambda architecture
The batch layer utilizes a distributed processing system to process all available data. As processing takes time, the batch layer can push fewer updates. Additionally, to fix errors the system needs to recompute the complete dataset. Such a batch processing system was Hadoop in its early days. Since then its ecosystem has grown to cover all layers of the lambda architecture.
The speed layer processes the most recent data and provides a (near) real-time view of the data. In its original form, it did not aim for completeness as it tried to fill the gap caused by the batch layer’s lag. But, real-time is nowadays is a business need.
Use cases may be streaming ETL; data enrichment; or trigger event detection (e.g. credit card fraud detection). Further, stream processing can come in different flavors:
- An event at a time (e.g. with Apache Storm/ Flink).
- Micro-batching events together (e.g. with Apache Spark).
- A sliding event window. It provides in-order event and processing (only-once, at-least-once, and at-most-once).
Finally, the serving layer stores output from the batch and speed layers. It also responds to ad-hoc queries. Some available technologies include Apache Druid, Apache Cassandra, Apache HBase, or Apache Impala.
A real-world example
The next figures show a data pipeline used to gather and process environmental data like temperature or humidity. The first figure uses open-source components for the pipeline. This makes it possible to deploy it on-premises or in any IaaS (Infrastructure as a Service) cloud. The second figure uses PaaS (Platform as a Service) level components in Microsoft Azure [3].
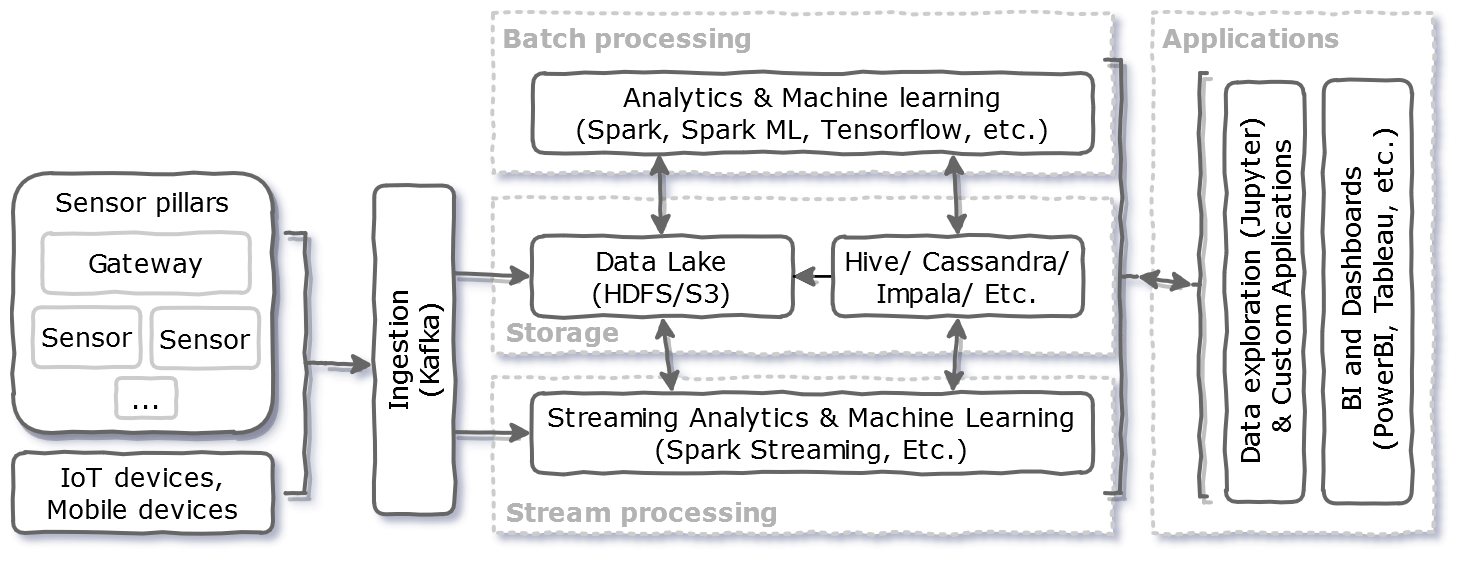
Architecture for processing environmental data on-premises or on an IaaS cloud
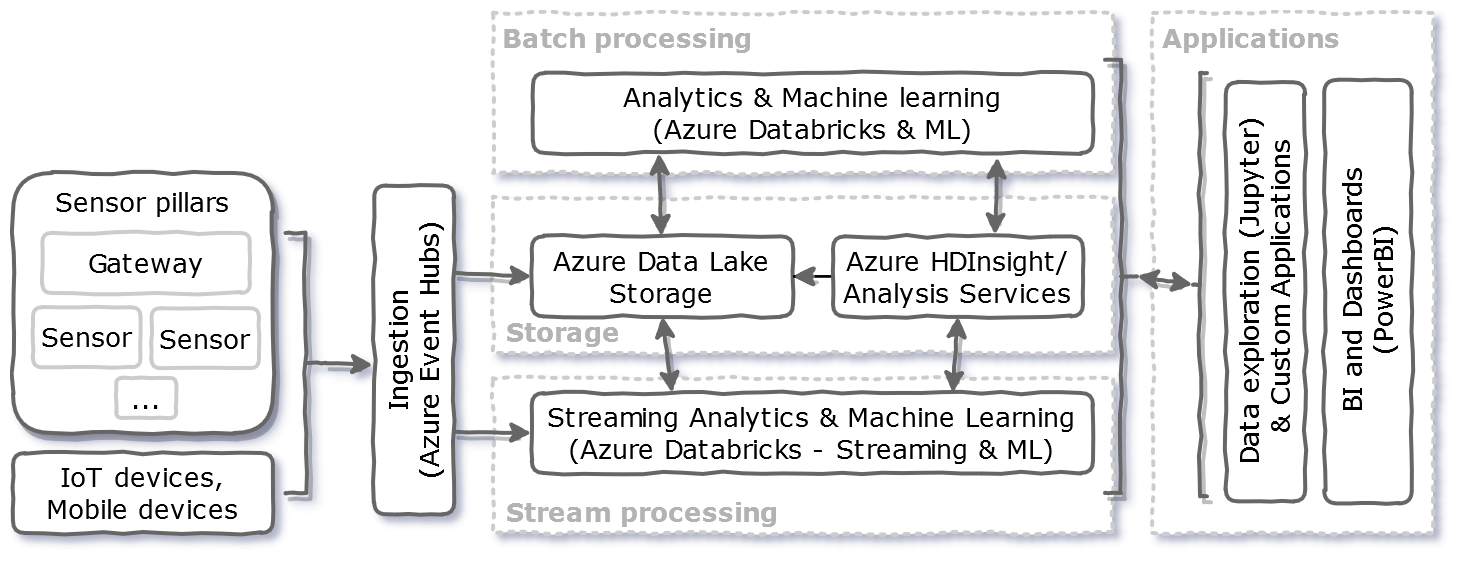
Same architecture with PaaS components from Azure
This pipeline originates from a project where it collected data from a large number of IoT devices. The devices were sensors attached to pillars and drilled into the soil. There were also gateways embedded in the pillars. These relay data via cellular network to the ingestion components of the pipeline. There Kafka producers ingest the data received into many topics. Kafka makes the new data available for the batch and streaming pipelines. Kafka acts as a buffer for services next in the pipeline, allowing them to “catch up” during burst/ peak load cases. As a side note, Kafka may act also as a permanent data store. Alternative services for ingestion could be Amazon Kinesis, Google Pub/Sub, or Azure Event Hubs.
The batch processing pipeline stores incoming data in persistent storage like HDFS or S3. This is the master data, called “Data Lake” (stores both structured and unstructured data). Next Spark processes the data and stores the results for further analytics. The data is further accessible for example via Hive or Cassandra.
Azure HDInsight is a PaaS Hadoop distribution for Azure. It is like Amazon Elastic MapReduce (EMR) on Amazon AWS. Services include Apache Hive for managing structured data. Apache Spark and Azure Databricks are for stream processing (micro-batching). This latter also fills the latency gap from batch processing.
Finally, the “Applications” block contains more components. These provide API-s and user interfaces for data exploration, visualization, and business intelligence.
In summary, this post detailed what a data pipeline is, how it compares to ETL pipelines. I presented the difference using a real-world pipeline for collecting environmental data. I showed two implementations for this pipeline. The first one is using open source components for on-premises or IaaS clouds. The second one is using Microsoft Azure PaaS components.
Additional reading material
- http://www.dataandgraphs.com/uncategorized/building-a-hadoop-data-pipeline-where-to-start/
- https://community.cloudera.com/t5/Community-Articles/Define-and-Process-Data-Pipelines-in-Hadoop-With-Apache/ta-p/246430
- https://towardsdatascience.com/data-science-for-startups-data-pipelines-786f6746a59a
- https://dzone.com/articles/what-is-a-data-pipeline
- https://www.linkedin.com/learning/extending-hadoop-for-data-science-streaming-spark-storm-and-kafka/